
AI Observability
for Production Agents
See where workflows break, what they cost, and whether outputs are good enough to ship. Built for teams working in .NET, Python, and JavaScript.
No credit card required to start.
5-minute set up.


Turn Production Evidence Into Reliable Releases
Connect every signal across the production loop.
AI agents, LLM apps, RAG systems, and copilots don’t follow simple request-response paths. Trace behavior, debug failures, control spend, and evaluate quality across real production workflows.

Why Production AI Is Hard to
Understand and Operate

No Clear Execution Path
AI agents do not follow a simple request-response path. A single answer can move through prompts, retrieval, tool calls, retries, model responses, and custom workflow logic. Without a full trace, teams are left guessing what happened.

Failures Do Not Always Look Like Errors
An agent can return a response while skipping a tool, using stale context, retrieving the wrong source, or failing the task. Teams need AI-specific debugging context, not just application logs.

AI Cost is Shaped by Runtime Behavior
LLM spend changes with prompt size, model choice, retries, tool loops, retrieval patterns, evaluation runs, and workflow volume. Teams need cost and token usage tied to the execution path, not just pricing tables.

Successful Responses Do Not Guarantee Quality
A response can be fast, complete, and valid-looking while still containing hallucinations, being ungrounded, unsafe, irrelevant, or unhelpful. Teams need repeatable evaluations connected to production traces.
See Progress AI Observability in Action
Explore product views that help teams trace AI behavior, debug agent failures, analyze cost and token usage, and evaluate output quality from real AI execution data.
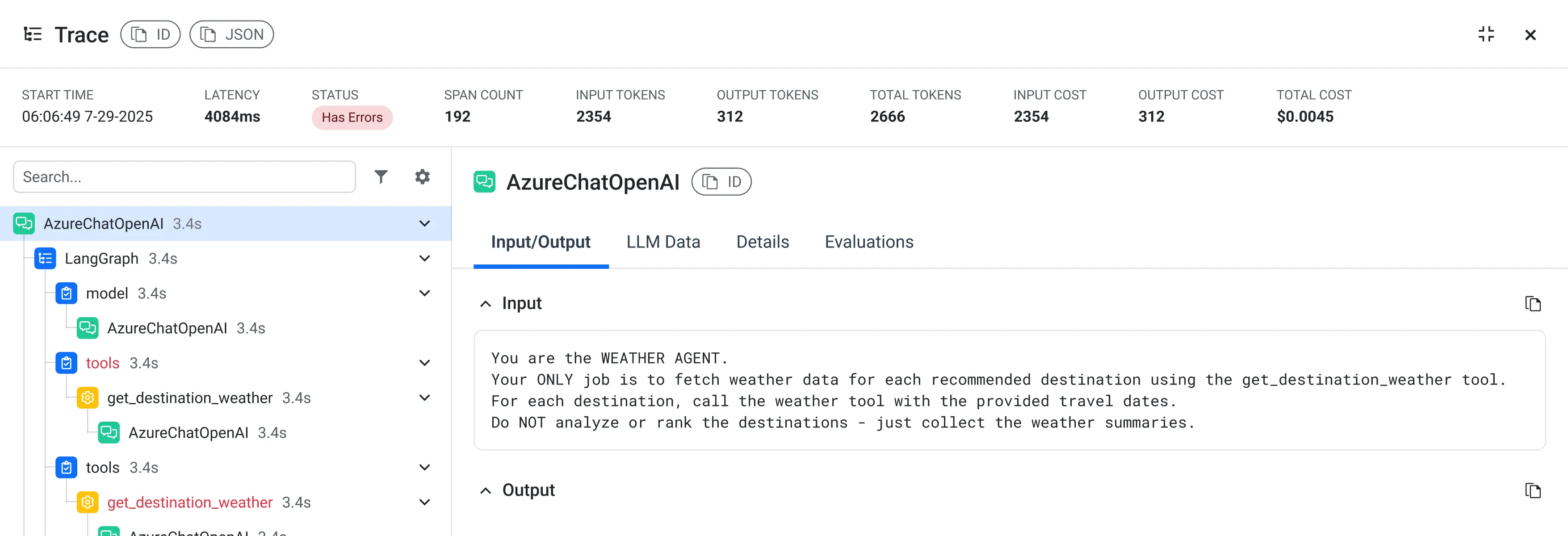
Understand What your Agent Did
Capture the full path of an agent run across prompts, models, tools, retrieval steps and outputs. See how decisions unfold across multi-step and multi-agent workflows.
What’s measured: spans, model calls, tool calls, retrieval steps, latency, token usage, outputs
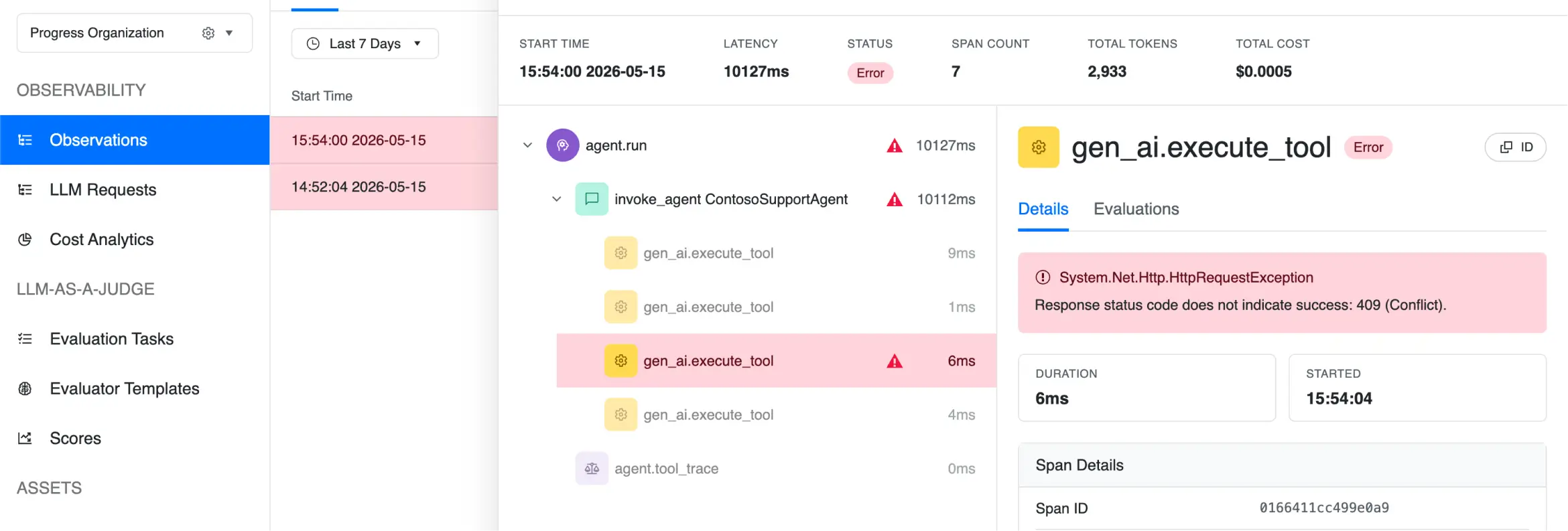
Investigate Why it Failed
Pinpoint where behavior broke down and what to fix next. Diagnose failures using trace-level context from real agent runs.
What’s measured: errors, failed spans, retries, workflow status, tool failures, latency spikes
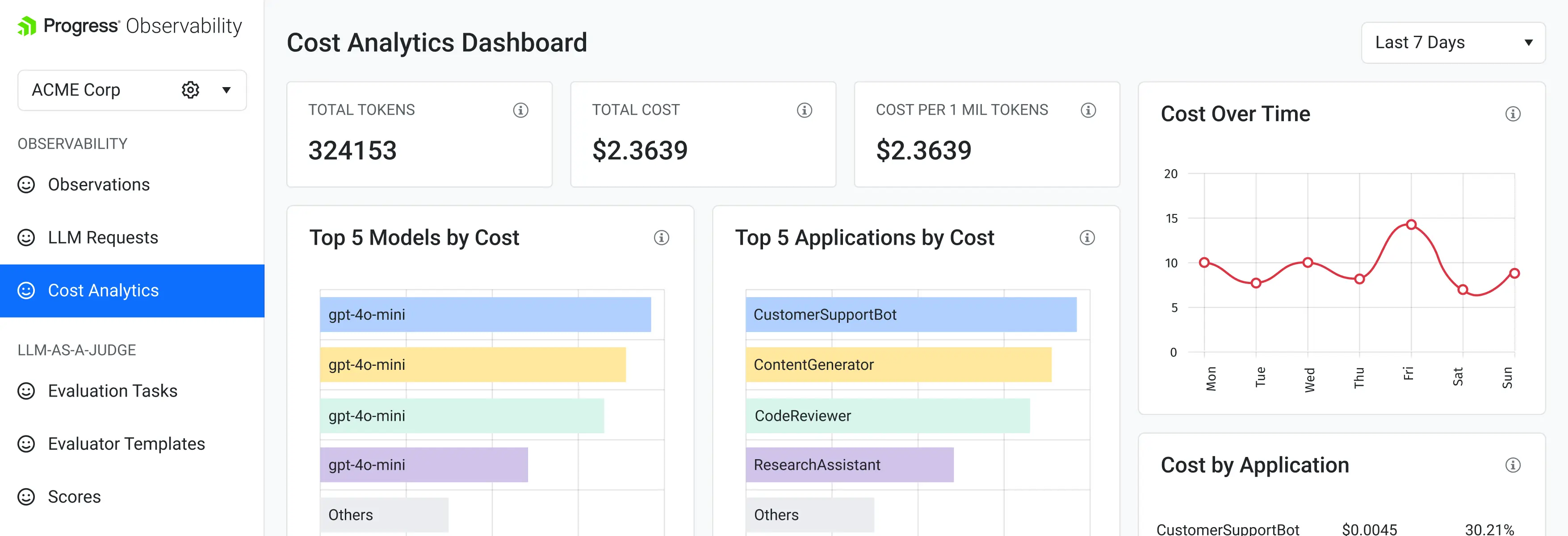
Understand What it Costs
Track LLM spend across agents, workflows, models and providers. Identify what is driving cost so teams can optimize usage before it scales.
What’s measured: estimated cost, input tokens, output tokens, cost by model, cost by workflow, usage units
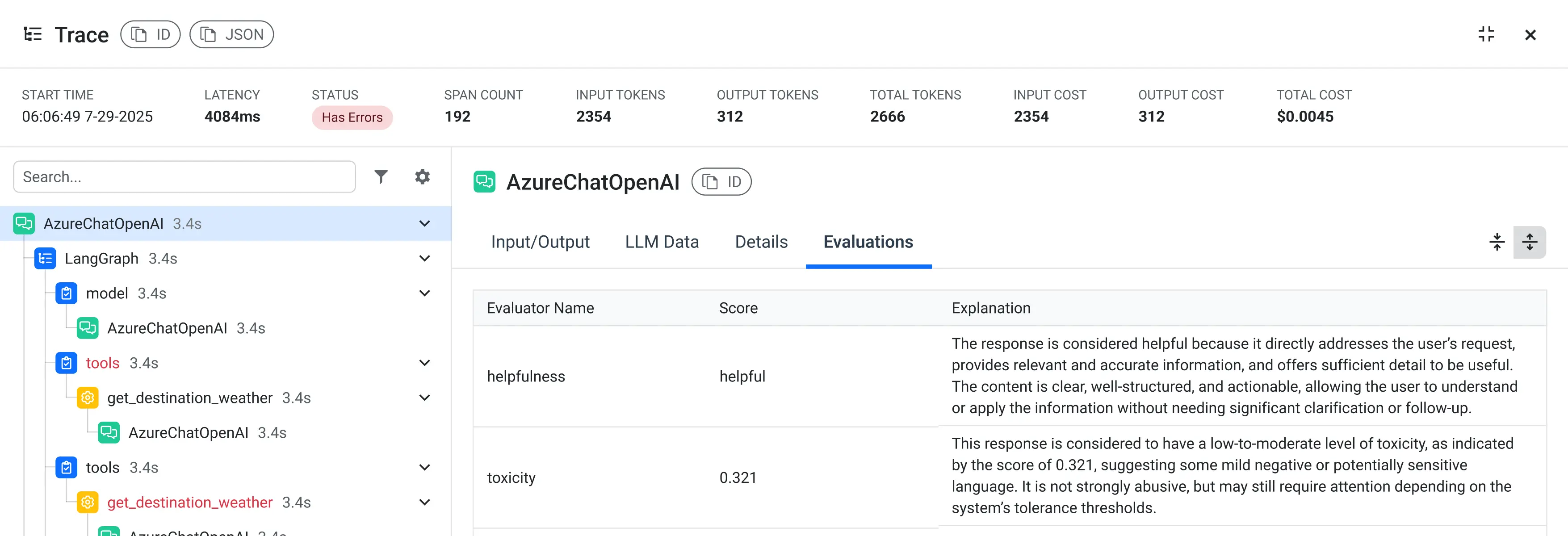
Understand How Well it Performs
Run LLM-as-a-judge evaluations on captured traces. Score quality, usefulness and policy alignment. Compare prompt, model or workflow changes side by side using real execution data.
What’s measured: evaluation scores, judge verdicts, quality trends, weak responses, prompt/model comparisons, before/after results
Trace Your First AI Agent in Minutes.
Install the SDK, add a few lines of code, and start capturing traces from live agent runs. See LLM calls, tool use, retrieval steps, latency, token usage, and cost in your dashboard.
Sign up for free · No credit card required
Get Started in Minutes
// .NET - Install & Instrument
// 1. Install
dotnet add package Progress.Observability.Instrumentation
// 2. Instrument
chatClient = chatClient.AddObservability(options =>
{
options.AppName = Environment.GetEnvironmentVariable("OBSERVABILITY_APP_NAME")!;
options.ApiKey = Environment.GetEnvironmentVariable("OBSERVABILITY_API_KEY")!;
});# Python - Install & Instrument
# 1. Install
pip install progress-observability
# 2. Instrument
from progress_observability import Observability; import os
Observability.instrument(
app_name=os.getenv("OBSERVABILITY_APP_NAME"),
api_key=os.getenv("OBSERVABILITY_API_KEY")
)// TypeScript - Install & Instrument
// 1. Install
npm install progress-observability
// 2. Instrument
import { Observability } from 'progress-observability';
Observability.instrument({
appName: process.env.OBSERVABILITY_APP_NAME,
apiKey: process.env.OBSERVABILITY_API_KEY
});“We cut our agent debugging time from 4 hours to 20 minutes. Being able to see the full trace - prompts, retrieval, tool calls - in one view changed how our team works.”
Early Access Program participant
Who It’s For
From debugging to governance, built around real AI workflows.
For Developers
Debug Agent Failures in Minutes, Not Days
- Find where behavior broke down across prompts, retrieval, tools, model calls, retries, and workflow logic
- Trace hallucinations and weak responses to their source
- Detect loops, timeouts, skipped tools, and cascading failures
For Engineering Leaders
Control reliability, performance, and cost
- See agent behavior across workflows, environments, models, providers, and teams
- Identify inefficient agent behavior and expensive patterns
- Compare cost, performance, and output quality
For Enterprise Teams
Scale AI systems with control and visibility
- Maintain trace history and audit trails
- Manage access, retention, and data residency requirements
- Support SSO, governance controls, data residency options, and volume-based plans
Pricing
Simple, predictable pricing. Start free, scale as you grow. No surprises, no hidden fees.
Free ForeverFor developers testing early agent prototypes
per month
Includes 10,000 units
Retention: 7 days
StarterFor small teams deploying their first live AI agents
per month
Includes 200,000 units
Retention: 30 days
$8 USD per additional 100K units
ProFor teams running production AI agents at scale
per month
Includes 1,000,000 units
Retention: 60 days
$8 USD per additional 100K units
EnterpriseFor organizations scaling governed AI applications
per month
Custom trace volume
Retention: Infinite

Works with Your Stack
The Progress AI Observability Platform integrates with the tools, frameworks and platforms teams already use to build and run AI agents.
- Languages & SDKs: .NET (C#), Python, JavaScript/TypeScript
- Agent Frameworks: Semantic Kernel, LangChain, LlamaIndex, AutoGen, Microsoft Agent Framework
- LLM Providers: Azure OpenAI, OpenAI, Anthropic
- AI Tooling: Microsoft.Extensions.AI, Microsoft AI Foundry, Progress RAG
- Enterprise SSO: Okta, Azure AD, SAML
- Open‑Source Models (OSS): Llama 2/3, Mistral, Mixtral, Falcon, Gemma, etc.
Development and Production: Use the same observability workflow to debug locally, validate changes, and investigate production behavior.


Frequently Asked Questions
The most common questions teams ask when evaluating AI observability for production agents.
Capability Specific FAQs

Ready to See What Your AI Agents Are Actually Doing?
Get end-to-end visibility into your AI agents in minutes. Free to start, built to scale.